I’ve been using Conductor for the past month. It lets you run Claude Code (or Codex) in parallel across multiple git worktrees. It’s changed how I work.
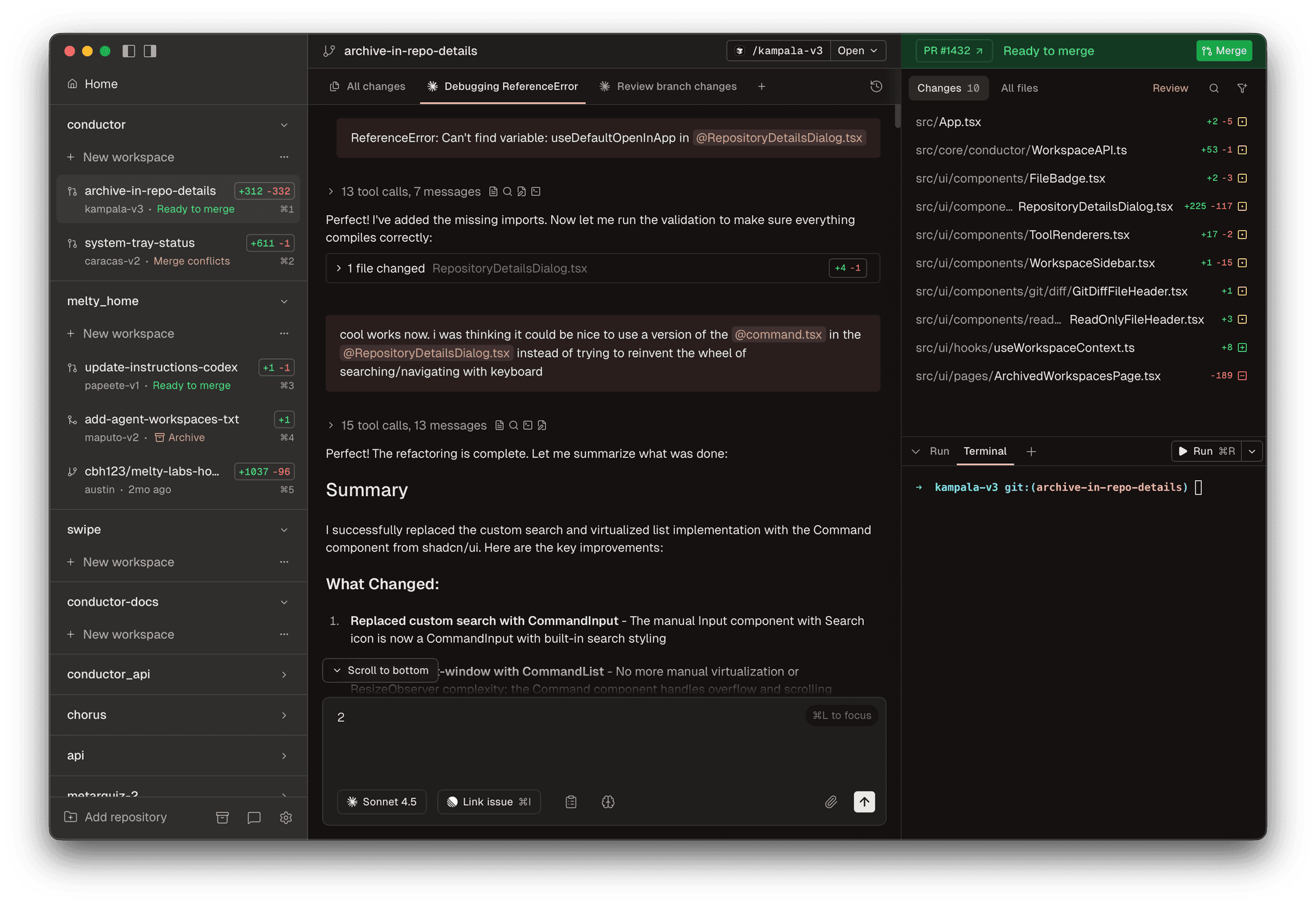
My main use case is exploration and prototyping. I’ll spin up a few agents to try different approaches to the same problem. While they work, I do other things. Check back later, see what stuck.
The parallelism is the obvious win. But here’s what’s underrated: when agents run in parallel, time doesn’t matter. It doesn’t matter if a task takes 5 minutes or 45 minutes. You’re not watching. You’re not waiting. You’re doing something else. Let the agent take its time and get it right.
The other unlock is efficient worktree usage. Each agent gets its own isolated environment. No stepping on each other. No merge conflicts mid-task.
Getting Good Output
Here’s the thing about coding agents: they need to be able to verify their own work.
This is the most important part. If an agent can’t check whether it succeeded, you’re just hoping it worked. Hope isn’t a strategy.
What verification looks like for me:
- Strong typing. TypeScript everywhere. The compiler catches things before you do.
- Precommit hooks. Linting and formatting run automatically. Agents can’t ship broken code.
- Test endpoints. For backend work, agents can hit real endpoints and test payloads.
- End-to-end tests. Good E2E coverage means agents can run tests and know if they broke something.
- A browser. For UI work, I use agent-browser so agents can actually see and interact with what they built.
The more feedback loops you give the agent, the better the output.
One more thing: agents love CLIs. If your software can be driven from a command line, even just to start, it’s extremely helpful. CLIs give agents tight feedback loops. Run a command, see the result, adjust. No clicking around, no guessing.
Models Matter
I’ve been switching between GPT-5.2-Codex and Claude Opus 4.5. They’re different.
GPT-5.2-Codex (with reasoning set to X-High) is the smartest, but slowest. It’s great for figuring out really hard problems. When I’m stuck on something gnarly, this is what I reach for.
Opus 4.5 has great taste. It cares about the shape of the code, uses good patterns, and thinks about developer experience.
Sometimes I’ll have Opus 4.5 come up with the plan and GPT-5.2-Codex implement. Other times I’ll have Codex implement and Opus 4.5 review and suggest refactors. Different strengths, use both.
Keep It Simple
One caveat: this works best with clear, scoped tasks. “Add a button that does X” is better than “refactor the auth system.” Agents thrive on specificity.
Things I Want to Try
I’ve heard that instructing models to use tracer bullets: getting a minimal end-to-end implementation working first before filling in the details. The idea is the agent proves the path works before investing in the full solution.
If you haven’t tried running agents in parallel, give it a shot. It’s a different way to work.